

Geolocation
You can usually tell where a picture was taken by recognizing certain location cues within the photo. Major landmarks like the Great Wall of China or the Tower of London are immediately recognizable and fairly easy to pinpoint, but how about when the photo lacks any familiar location cues, like a photo of food, of pets, or one taken indoors?
People do fairly well on this task by relying on all sorts of knowledge about the world. You could figure out where a photo was taken by looking at any words found on the photo, or by looking at the architectural styles or vegetation.
Humans are hardwired to recognize a picture’s location without the need to be trained. Machines, on the other hand, struggle at this.
Now, a team at Google have been able to train a deep-learning computer to figure out the location of a photo without relying on metadata and just the pixels. They’ve even come up with a clever way to learn the location of a photo taken indoors, or ones with no geolocation cues. And it’s all pretty straightforward that it’s a wonder why no one’s ever done it before.
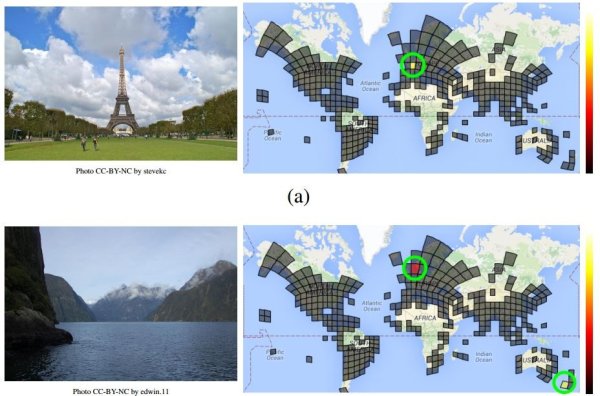
PlaNet
Led by computer vision specialist Tobias Weyand, the team applied a fairly straightforward approach. They started by dividing regions of the world in grids of more than 26,000 squares, each of different sizes.
The size of a region’s square depends on the number of photos taken in that area. Big cities have a smaller and more detailed slice since a vast majority of photos are snapped in these areas. More remote regions require less detailed grids as fewer photos are taken there.
The team then created an enormous database of geolocated images and correlated them to their respective squares on the grid. The database consists of 126 million images and their Exif data, 91 million of which were used to teach a neural network to locate where each image was photographed, while the remaining 34 million were used to validate the dataset.
The network, now named PlaNet, was then tested by feeding it 2.3 million geotagged images from Flickr and seeing how many it could correctly identify.
Man vs. Machine
According to Weyand and this team, “PlaNet is able to localize 3.6 percent of the images at street-level accuracy and 10.1 percent at city-level accuracy.” Furthermore, PlaNet was able to specify the country of origin in 28.4% of the photos, and which continent in 48%.

These numbers may seem low, but they’re actually very good. To show that, the team pitted PlaNet against 10 well-traveled humans. The test involved an online game, in which a random image taken from Google Street View was shown, and the participant was required to pinpoint the location from where it was taken. You can take the test yourself at www.geoguessr.com to see how well you do.
The results were surprising. The team said that “PlaNet won 28 of the 50 rounds with a median localization error of 1131.7 km, while the median human localization error was 2320.75 km.”
“[This] small-scale experiment shows that PlaNet reaches superhuman performance at the task of geolocating Street View scenes,” said Weyand.
Although PlaNet doesn’t yet have the advantage of possessing knowledge of vegetation and architecture, it does have an edge over humans. “We think PlaNet has an advantage over humans because it has seen many more places than any human can ever visit and has learned subtle cues of different scenes that are even hard for a well-traveled human to distinguish.”
What’s even more startling is how little memory the network runs on. “Our model uses only 377 MB, which even fits into the memory of a smartphone,” say Weyand.