

How machines deal with comprehending human languages is called Natural Language Understanding (NLU), and revolutionary changes in this technology have given us the many virtual assistants we have today. However, NLU still has many obstacles to go through due to the ambiguous nature of the countless languages all over the world.
Parsey and SyntaxNet
Now, Google claims they’re cutting through these difficulties as they announced the open sourcing of a neural network software developed with TensorFlow, SyntaxNet, together with…Parsey McParseface, apparently an English parser.
Parsing, in linguistics, is the breaking down of sentences into their component parts to define what each part means. Experts assert that this is a first key component in NLU systems.
In this case, SyntaxNet is the framework for such an approach, taking a sentence as input and tagging each word with its function in that sentence. This was designed to be trained based on the data you have, and create a model for understanding such data linguistically.
Parsey McParseface, on the other hand, is a ready-made version, capable of accurately analyzing the linguistic structure of input in the English language. How both software processes all of this looks identical to the way we look at a dependency-based parse tree.
Cutting Through Ambiguity
Google points out that humans do an almost seamless job of dealing with these misinterpretations, basically because of how we incorporate logic and experience in the matter, effectively disregarding senseless syntactic structures.
Indeed, a single complex sentence can possibly have thousands of possible structures that vary on how we should understand it. This is one of the major hurdles of NLU.
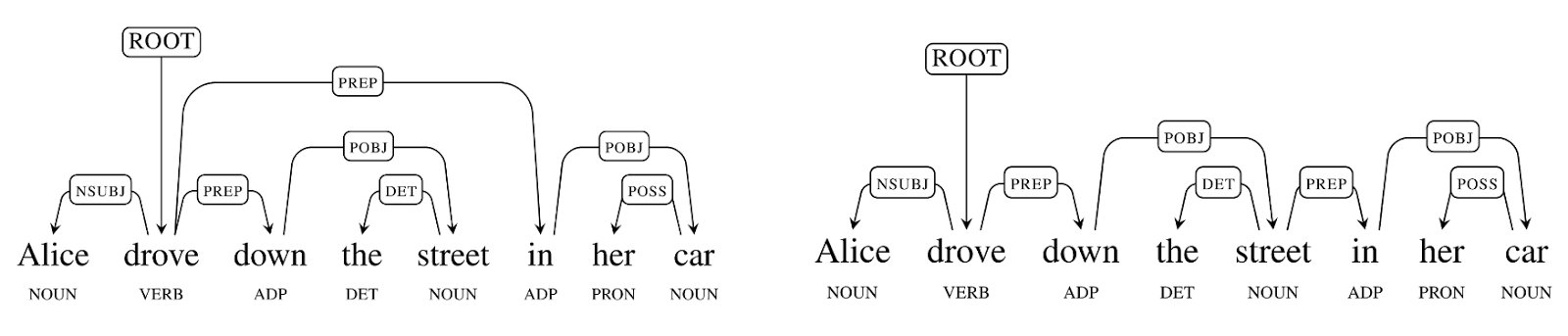
In their own study, Google gave randomly drawn English sentences to Parsey McParseface which it processed with over 94% accuracy.
Google says that their data suggest that they’re close to reaching human performance with this software. With their characteristic ambition, they intend to develop this framework across all languages.