

Hitting the Books
Reading comprehension is a skill that measures how a person is able to grasp and understand what they are reading. Improving this involves reading and lots of practice to gauge and discern differing usage and contexts of words. The same thing applies for artificial intelligence.
Facebook released several data sets that it has been using to train its home-grown neural networks. Some of these are texts of classic novels, such as Rudyard Kipling’s The Jungle Book, J. M. Barrie’s Peter Pan, and Lewis Carroll’s Alice’s Adventures in Wonderland; others are collections of fairy stories, such as Andrew Lang’s Fairy Books, Nathaniel Hawthorne’s Twice-Told Tales, and Oscar Wilde’s The Happy Prince and Other Tales. Most of these were obtained from the free online library Project Gutenberg.
By training its AI on these books, Facebook is trying to ensure that its AI is able to process what it’s reading and is able to make logical connections. Central to this is what Facebook calls the “Children’s Book Test,” which it uses as a metric to ascertain the progress of the AI.
In their paper, Facebook researchers trained a neural network using a sample of books from the list. After this, they presented it with short excerpts from the stories it had not read. The AI was then asked to choose a word from a list of options which would fill the gap left by a missing word in the final sentence.
Reading Between the Lines
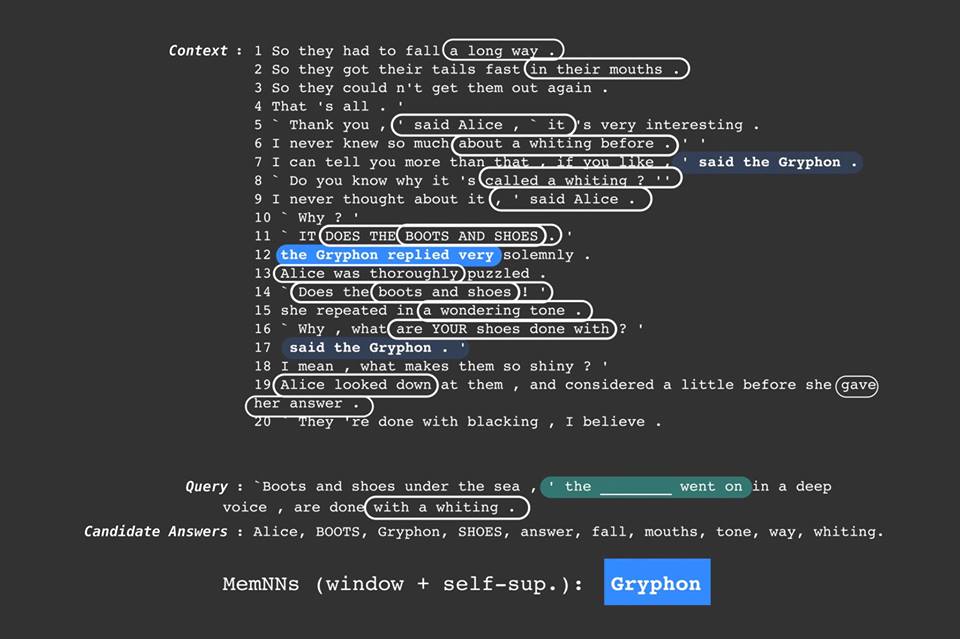
By being able to answer such questions, the researchers believe that it demonstrates that an AI can make decisions or judgements by drawing on a situation’s wider context. This skill is crucial in representing and remembering complex pieces of information, and it would improve the AI’s performance in situations requiring such processing outside of reading; another Facebook-devised intelligence test is geared to comprehending the relationships between ideas in short stories.
“Our team taught the computer to look at the context of a sentence and much more accurately predict those more difficult words—nouns and names—which are often the most important parts of sentences,” Facebook’s CEO Mark Zuckerberg explained in a post.
“The computer’s predictions were most accurate when it looked at just the right amount of context around relevant words—not too much and not too little,” he said, calling it the “Goldilocks Principle.”