

It’s been just over a month since OpenAI dropped its long-awaited GPT-5 large language model (LLM) — and it hasn’t stopped spewing an astonishing amount of strange falsehoods since then.
From the AI experts at the Discovery Institute’s Walter Bradley Center for Artificial Intelligence and irked Redditors on r/ChatGPTPro, to even OpenAI CEO Sam Altman himself, there’s plenty of evidence to suggest that OpenAI’s claim that GPT-5 boasts “PhD-level intelligence” comes with some serious asterisks.
In a Reddit post, a user realized not only that GPT-5 had been generating “wrong information on basic facts over half the time,” but that without fact-checking, they may have missed other hallucinations.
The Reddit user’s experience highlights just how common it is for chatbots to hallucinate, which is AI-speak for confidently making stuff up. While the issue is far from exclusive to ChatGPT, OpenAI’s latest LLM seems to have a particular penchant for BS — a reality that challenges the company’s claim that GPT-5 hallucinates less than its predecessors.
In a recent blog post about hallucinations, in which OpenAI once again claimed that GPT-5 produces “significantly fewer” of them — the firm attempted to explain how and why these falsehoods occur.
“Hallucinations persist partly because current evaluation methods set the wrong incentives,” the September 5 post reads. “While evaluations themselves do not directly cause hallucinations, most evaluations measure model performance in a way that encourages guessing rather than honesty about uncertainty.”
Translation: LLMs hallucinate because they are trained to get things right, even if it means guessing. Though some models, like Anthropic’s Claude, have been trained to admit when they don’t know an answer, OpenAI’s have not — thus, they wager incorrect guesses.
As the Reddit user indicated (backed up with a link to their conversation log), they got some massive factual errors when asking about the gross domestic product (GDP) of various countries and were presented by the chatbot with “figures that were literally double the actual values.”
Poland, for instance, was listed as having a GDP of more than two trillion dollars, when in reality its GDP, per the International Monetary Fund, is currently hovering around $979 billion. Were we to wager a guess, we’d say that that hallucination may be attributed to recent boasts from the country’s president saying its economy (and not its GDP) has exceeded $1 trillion.
“The scary part? I only noticed these errors because some answers seemed so off that they made me suspicious,” the user continued. “For instance, when I saw GDP numbers that seemed way too high, I double-checked and found they were completely wrong.”
“This makes me wonder: How many times do I NOT fact-check and just accept the wrong information as truth?” they mused.
Meanwhile, AI skeptic Gary Smith of the Walter Bradley Center noted that he’s done three simple experiments with GPT-5 since its release — a modified game of tic-tac-toe, questioning about financial advice, and a request to draw a possum with five of its body parts labeled — to “demonstrate that GPT 5.0 was far from PhD-level expertise.”
The possum example was particularly egregious, technically coming up with the right names for the animal’s parts but pinning them in strange places, such as marking its leg as its nose and its tail as its back left foot. When attempting to replicate the experiment for a more recent post, Smith discovered that even when he made a typo — “posse” instead of “possum” — GPT-5 mislabeled the parts in a similarly bizarre fashion.
Instead of the intended possum, the LLM generated an image of its apparent idea of a posse: five cowboys, some toting guns, with lines indicating various parts. Some of those parts — the head, foot, and possibly the ear — were accurate, while the shoulder pointed to one of the cowboys’ ten-gallon hats and the “fand,” which may be a mix-up of foot and hand, pointed at one of their shins.
We decided to do a similar test, asking GPT-5 to provide an image of “a posse with six body parts labeled.” After clarifying that Futurism wanted a labeled image and not a text description, ChatGPT went off to work — and what it spat out was, as you can see below, even more hilariously wrong than what Smith got.
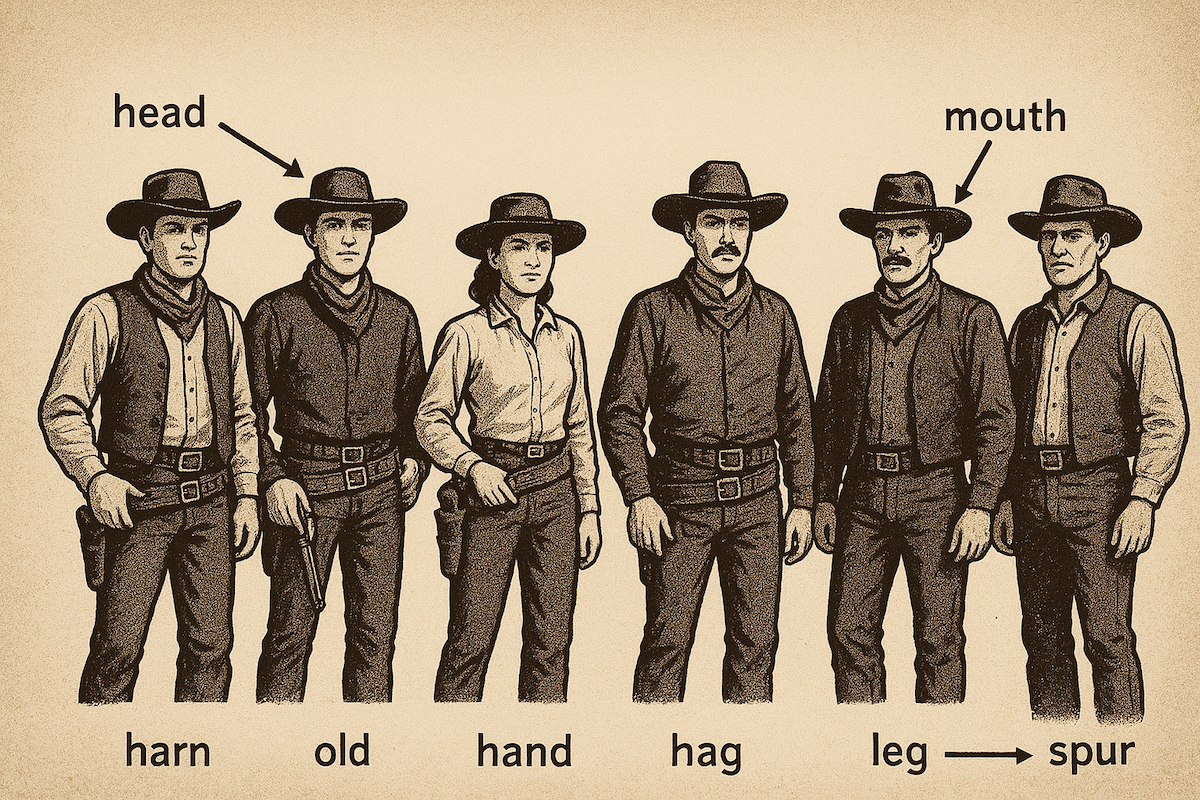
It seems pretty clear from this side of the GPT-5 release that it’s nowhere near as smart as a doctoral candidate — or, at very least, one that has any chance of actually attaining their PhD.
The moral of this story, it seems, is to fact-check anything a chatbot spits out — or forgo using AI and do the research for yourself.
More on GPT-5: After Disastrous GPT-5, Sam Altman Pivots to Hyping Up GPT-6