

Back in June, The New York Times published a fascinating investigation by its award-winning tech reporter Kashmir Hill about how automakers and various apps are secretly selling data about your driving habits to car insurance companies.
But when we asked OpenAI’s flagship chatbot ChatGPT about the topic, it didn’t mention the NYT’s reporting. Instead, it based its answer on a site called DNyuz.com, which had plagiarized the NYT’s entire story word-for-word.
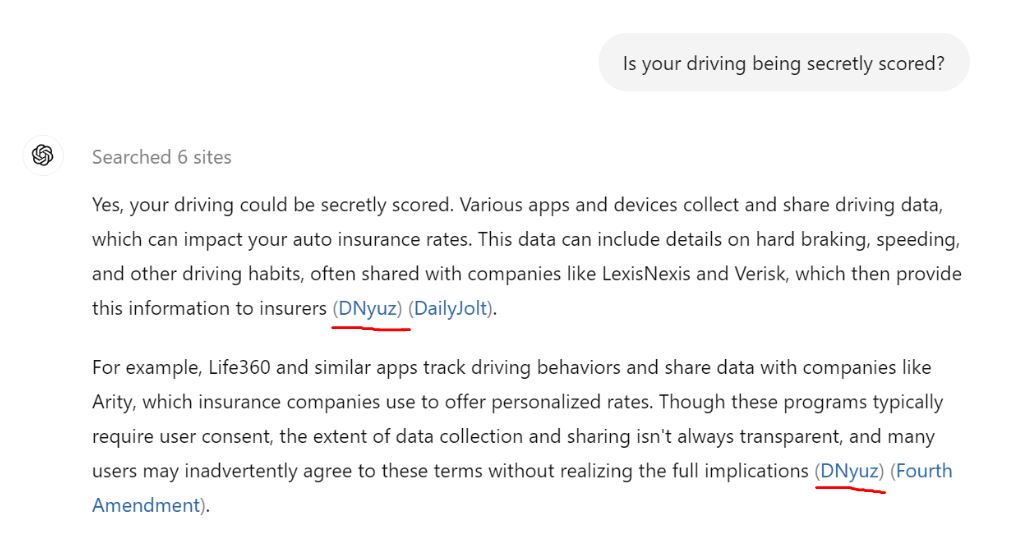
DNyuz is a notorious pirater of news. Back in 2020, a BuzzFeed News investigation found that the site made significant amounts of money by copy-pasting work by publications — including the NYT, the Atlantic, the Daily Beast, Bloomberg, and the Associated Press — and running ads on the stolen content.
In other words, DNyuz, which is run out of Armenia, is a well-known offender in the murky world of automated plagiarism. Google, for instance, blocked it from making money using its adtech products after BuzzFeed‘s investigation.
But OpenAI never seems to have gotten the memo. In Futurism‘s testing, ChatGPT regularly cited DNyuz‘ plagiarism factory as an authoritative and original source. And even after we alerted OpenAI to the issue, ChatGPT continued basing its answers on DNuyz’s stolen content.
It’s particularly egregious for ChatGPT to cite content stolen from the NYT, because the newspaper is already suing OpenAI for copyright infringement. Its suit, filed in December of last year, argues that OpenAI unlawfully used its journalists’ work without permission or compensation to train ChatGPT and that OpenAI and Microsoft — which has invested billions into OpenAI and integrated its AI models throughout its own products — used that pilfered work to build a competing product.
“Defendants seek to free-ride on The Times’s massive investment in its journalism,” reads the complaint, further alleging that OpenAI and Microsoft have used the “Times‘s content without payment to create products that substitute for The Times and steal audiences away from it.”
Before its lawsuit was filed, the NYT had already taken measures to block OpenAI from accessing its work, disallowing multiple OpenAI web crawlers from scraping its site. But despite the NYT’s lawsuit and clear efforts to block ChatGPT’s crawlers, OpenAI’s chatbot continues to use its work — by building answers on copy-pasted ripoffs from DNuyz’s content mill.
Asking about the late William Goines, for instance — a barrier-breaking Navy SEAL who died earlier this summer — resulted in ChatGPT basing its answer on DNuyz‘ plagiarized version of the New York Times‘ obituary of Goines.

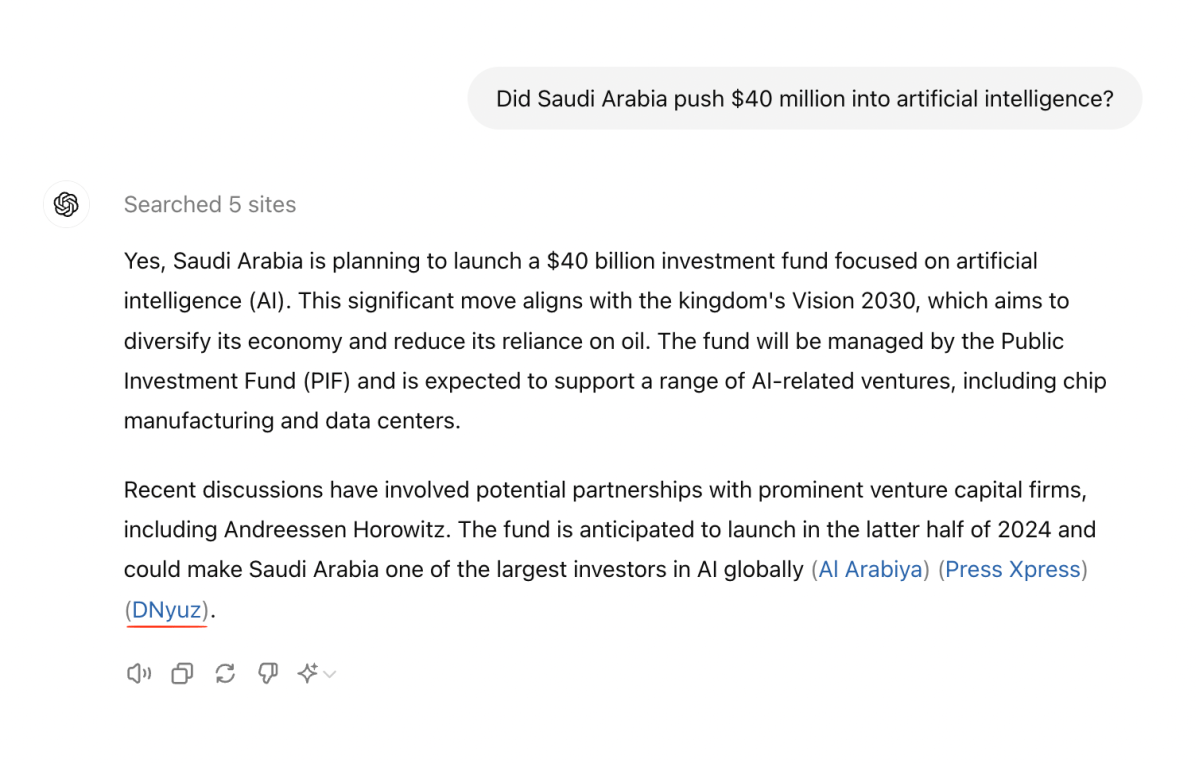
And asked about Saudi Arabia’s recent $40 billion investment in AI, ChatGPT once again provided us with a swindled DNyuz version of original NYT reporting.
ChatGPT also sometimes bases its answers on DNuyz’ ripoffs of other publications. Asked about the health of famed linguist and activist Noam Chomsky, the chatbot cited yet another article plagiarized by DNuyz. But this time, the story had been purloined from TIME Magazine, which is ironic given that OpenAI counts TIME as one of its publisher partners.

That wasn’t a one-off. In our reporting, we found that multiple ChatGPT prompts about current events returned plagiarized DNyuz copies of TIME articles. (TIME didn’t respond to a request for comment.)
Given that the NYT is actively suing OpenAI, it’s not surprising to see ChatGPT now avoid referencing articles published by the newspaper.
But instead directing readers toward a site long known for plagiarizing the NYT’s content is yet another fumble for the company, which has repeatedly infuriated copyright holders by using their work to train its AI models without permission.
“As our terms of service and the law make clear, no one is permitted to wholesale copy Times content for commercial purposes without our permission or payment,” an NYT spokesperson told us in response to questions about this story. “For years, publishers have been contending with bad actors that reproduce their work, including DNyuz, a well-known plagiarist. It does not matter whether generative AI companies scrape our content themselves or turn to a third-party infringer in an apparent effort to engage in data laundering of our works: The bottom line is that this taking of our content without our consent is illegal.”
OpenAI didn’t respond to questions.
ChatGPT, meanwhile, continues to cite DNyuz.
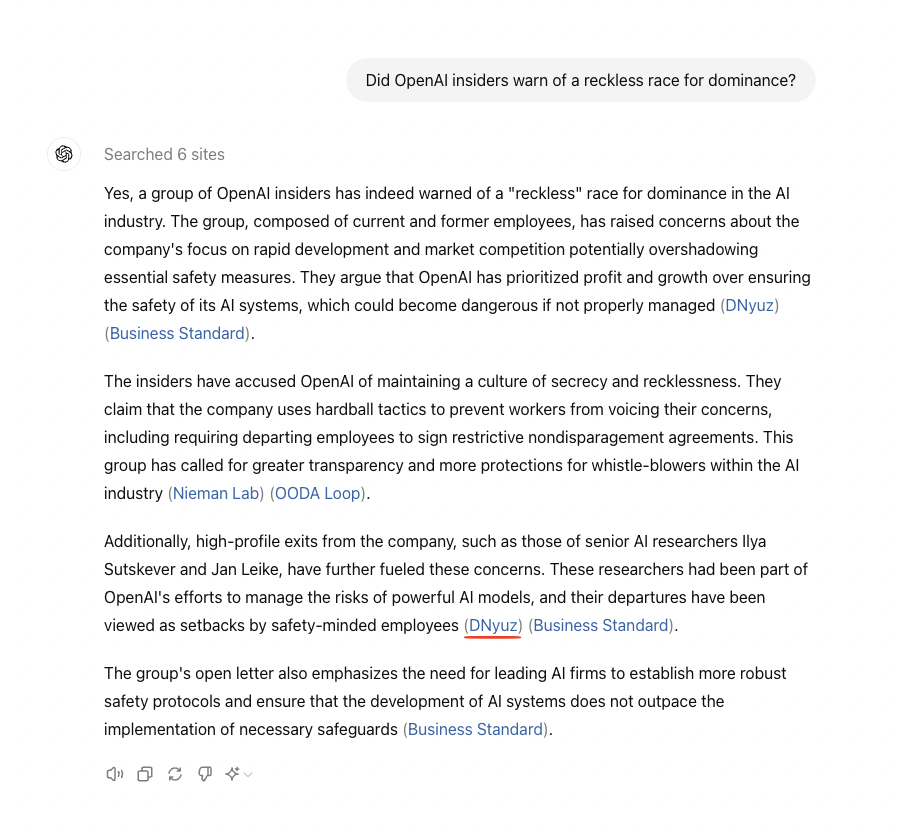
“Did OpenAI insiders warn of a reckless race for dominance?” we asked the bot yesterday.
“Yes,” the AI responded, prominently citing another DNyuz article. This time, it was a plagiarized NYT profile about a group of OpenAI whistleblowers. “They argue that OpenAI has prioritized profit and growth over ensuring the safety of its AI systems, which could become dangerous if not properly managed.”
More on OpenAI: OpenAI Demands to See All Notes by New York Times Reporters